NJU OS Lab M2: libco
南大的 OS Lab 还挺有意思的,这个 M2 是用 C 语言写一个小的有栈协程库,虽然比不上工业级协程库,但也是加深了对不少东西的认识,搓出来还是比较有成就感的。回头再讲一下有栈/无栈协程和协程怎么用罢。
什么是协程
协程,最简单粗暴的理解就是“可以挂起/恢复执行的函数”。这跟并行实际上没啥关系,倒是更像中断之类的。它能够完全在用户态下实现并发,而且也比操作系统提供的线程设施轻很多,最适合一些需要高 IO 高并发的场景;当然协程也可以用来做生成器之类的。
有栈协程和无栈协程是协程两种不同的实现方式,这里不细讲,只要知道有栈协程下协程自有栈空间即可。
lab 任务
牢蒋给了 3 个函数作为协程库的 API:
1 | struct co* co_start(const char *name, void (*func)(void *), void *arg); |
引用下他的要求1:
co_start(name, func, arg) 创建一个新的协程,并返回一个指向 struct co 的指针 (类似于 pthread_create)。
新创建的协程从函数 func 开始执行,并传入参数 arg。新创建的协程不会立即执行,而是调用 co_start 的协程继续执行。
使用协程的应用程序不需要知道 struct co 的具体定义,因此请把这个定义留在 co.c 中;框架代码中并没有限定 struct co 结构体的设计,所以你可以自由发挥。
co_start 返回的 struct co 指针需要分配内存。我们推荐使用 malloc() 分配。
co_wait(co) 表示当前协程需要等待,直到 co 协程的执行完成才能继续执行 (类似于 pthread_join)。
在被等待的协程结束后、 co_wait() 返回前,co_start 分配的 struct co 需要被释放。如果你使用 malloc(),使用 free() 释放即可。
因此,每个协程只能被 co_wait 一次 (使用协程库的程序应当保证除了初始协程外,其他协程都必须被 co_wait 恰好一次,否则会造成内存泄漏)。
co_yield() 实现协程的切换。协程运行后一直在 CPU 上执行,直到 func 函数返回或调用 co_yield 使当前运行的协程暂时放弃执行。co_yield 时若系统中有多个可运行的协程时 (包括当前协程),你应当随机选择下一个系统中可运行的协程。
还有一点值得注意:
main 函数的执行也是一个协程,因此可以在 main 中调用 co_yield 或 co_wait。main 函数返回后,无论有多少协程,进程都将直接终止。
实现
牢蒋已经在实验网站上给了很多有用的信息,非常的宝宝巴士,你往下看就能体会到了。
数据结构
侵入式链表
这个不多说,看看定义和初始化就行:
1 | typedef struct list_head { |
我们有一个全局变量,作为协程的链表头:
1 | list_head_t coroutine_list; |
struct co
最重要的数据结构就是我们亲爱的
struct co。由于我们要手搓的事有栈协程,协程里面起码应该有:
- 入口地址和参数
- 协程状态
- 上下文
- 协程自己的栈空间
万幸的是牢蒋已经给了个参考实现:
1 | enum co_status { |
这个 waiter 有可能可以去掉,不过目前我的实现中还是会依赖它。如果想要一个返回值的话似乎也得留着(?)
由于我打算用侵入式链表来组织
struct co,这个结构体里面还得加入链表节点;后面会发现如果不做
LRU 的话会有协程饥饿的问题,本🐭又不想真的写一个 LRU
队列,于是偷懒加了一个 call_cnt,
表示目前为止被调度到的次数。
这样的实现会有什么问题呢?
call_cnt溢出你就完蛋了!
于是最后的 struct co 如下:
1 | struct co { |
这里还有一个问题,为什么凭空多出来一个
__attribute__((aligned(16))) ?这是因为 x86_64
的调用规定需要你在执行 call 指令时, rsp 是 16 字节对齐的;
x86_32 则是要求 8
字节对齐。后面也会提到这点。此事在实验网站上亦有记载
值得一提的是,牢蒋还提醒我们声明一个全局变量,来标示现在正在运行的协程:
1 | struct co *curr_co = NULL; |
协程的分配与释放
这里写了两个工具函数 co_alloc 和
co_free:
1 | struct co *co_alloc(const char *name, void (*func)(void *), void *arg) { |
程序初始化和清理
还记得牢蒋的小贴士吗?main() 也是个协程!而且链表头
coroutine_list 也需要初始化。
我们可以利用 __attribute__((constructor)) 和
__attribute__((destructor)) 来实现初始化和清理:
1 | __attribute__((constructor)) void co_start_main() { |
下文会讲到 co_start() 实际上只是 co_alloc()
的包装。然后这里 main 协程显然已经在跑了,所以状态不能是
CO_NEW。
co_start()
协程并不是在 co_start()
就开始执行的,所以只要分配一个空协程就行:
1 | struct co *co_start(const char *name, void (*func)(void *), void *arg) { |
co_wait()
co_wait() 也比较简单,就一直等,等不到就
yield,等到了之后 free 掉:
1 | void co_wait(struct co *co) { |
co_yield()
这里是重头戏。我们需要选一个能跑的协程,然后保存/切换上下文。协程的选取、切换的时机、保存的方法都非常重要。
幸运的是,牢蒋也指定了切换上下文的方法: setjmp() /
longjmp()。他甚至告诉了我们怎么使用:
1 | void co_yield() { |
让我们思考一下:一个协程切出去了以后,别的地方调用
longjmp() 给切回来了,那么切回来的地方在哪里?显然就是
setjmp()
那里。切回来了之后干什么呢?那肯定是继续执行啊!所以 else
分支直接返回就行。
那上面的分支呢?上面的分支是第一次调用 setjmp()
的情况,这时候我们刚保存好当前协程的上下文,打算切出去。于是,co_yield()
具体该干什么已经很清楚了:
1 | void co_yield() { |
选协程
前面说过,我们用一种丑陋的方式大致实现了 LRU ,我们就来看看怎么选罢:
1 | /// Find a coroutine to run. |
为什么加 volatile ?留给读者做习题。
换上下文
选好协程之后,我们增加调用次数
call_cnt,然后进行切换就好了:
1 | curr_co = (struct co *)exec_co; |
别急!你是不是忘写了什么?是的,我忘写了 CO_NEW !如果
CO_NEW 也用 longjmp() 行不行呢?
你会死得很惨:
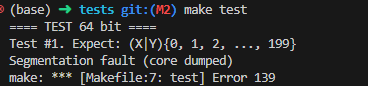
调试发现, CO_NEW
的线程还没有可用的上下文,你只能直接跳转过去:
1 | /// CO_NEW |
这个 stack_switch_call()
进行了一个换栈和跳转的工作。这里牢蒋给了一个参考实现:
1 | static inline void stack_switch_call(void *sp, void *entry, uintptr_t arg) { |
这里牢蒋显然挖了一个小坑:如果直接 jmp 过去的话怎么跳回来?因此 jmp 指令要改成 call 指令。
到了这里,可以回去睡觉了。
真的假的?
如果你这时候不偷懒跑一下测试,你会发现段错误了:
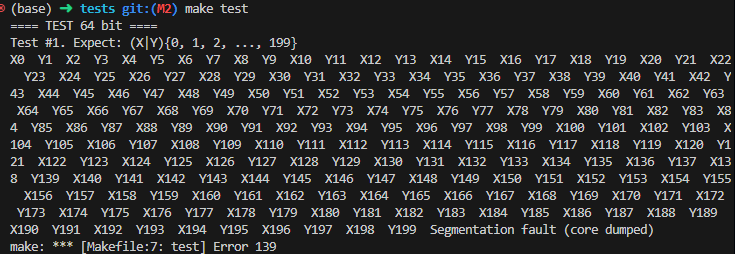
我们可以发现,与之前的段错误相比较,我们的协程是跑完之后才出问题的。讲到这里,饱饱们是不是很好奇,协程跑完之后去了哪里?去电影院了
我们用 gdb 看一下去了哪里。牢蒋的测例 1 中协程的入口点叫 work,我们在那里打个断点,然后一直 ni。
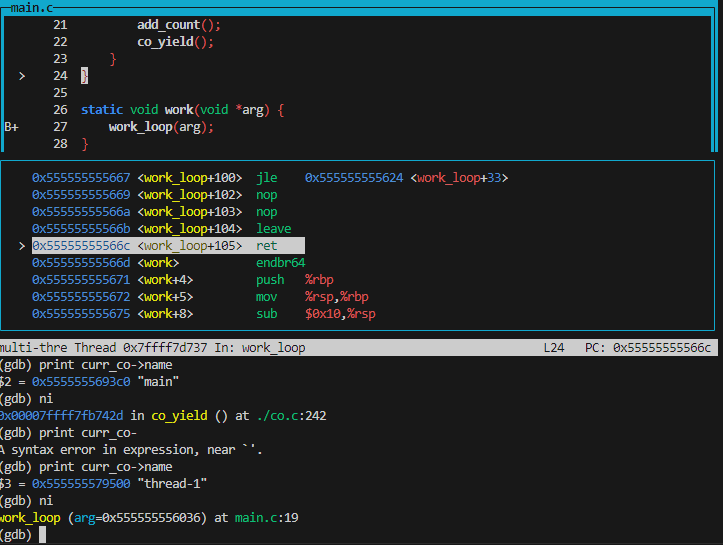
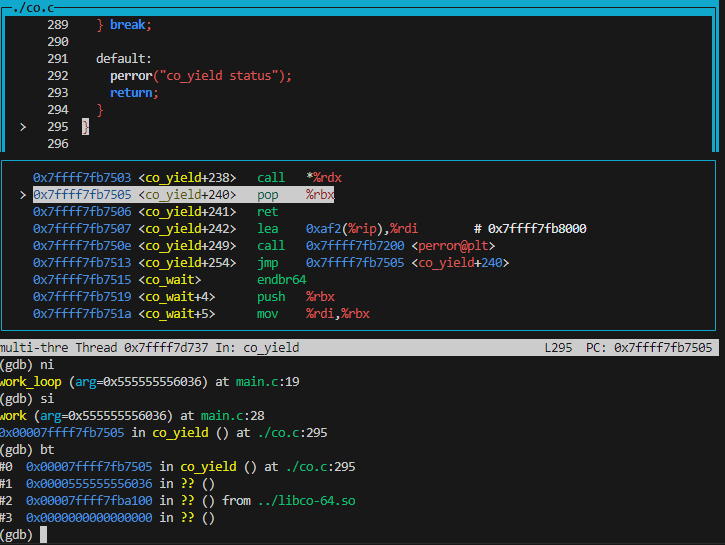
在 work() 的 ret 指令跑完过后,我们发现它回到了
co_yield() !上面这个 call 指令哪来的?注意到这个 call
跳转的不是一个绝对地址,前面提到过,我们需要
stack_switch_call() 跳转到选定协程的入口点
func ,这就是 call 指令的来源。也就是说,程序大概是运行到了
stack_switch_call() 后面,相当于一个 CO_NEW
状态的新协程执行完了。
知道了跳转到哪里,我们就比较好进行收尾工作了。首先,我们需要将刚跑完的协程的状态设置成
CO_DEAD,然后让出执行权。这里我直接将执行权让给了等待它的协程
waiter:
1 | stack_switch_call(((struct co *)exec_co)->stack + STACK_SIZE, exec_co->func, |
实际上也有用 co_yield() 出让执行权的写法。
stack_switch_call()
改到这里,我们重新跑一下,发现还是段错误了。调试发现,
exec_co 不知道指向哪里了:
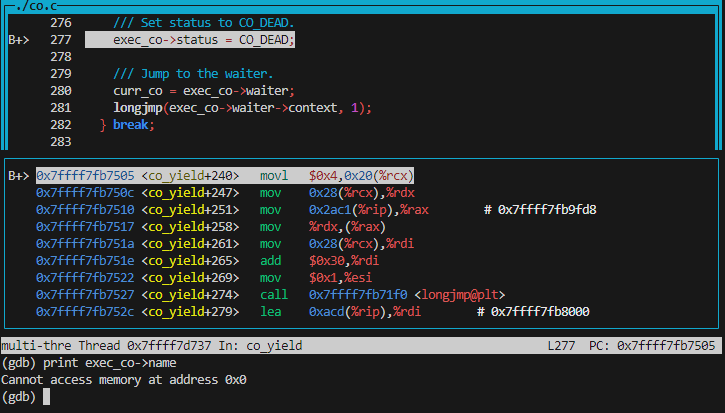
从 exec_co->status = CO_DEAD;
这句对应的汇编我们可以看出,这个 exec_co 的值实际上就是 rcx
寄存器的。这说明从调用 stack_switch_call()
到返回这段时间,我们的 rcx 寄存器被改变了。一个朴素的想法是调用前保存
rcx 寄存器的值,调用过后恢复。于是我们很容易对
stack_switch_call() 作如下修改(先不管 32 位):
1 | static inline void stack_switch_call(void *sp, void *entry, uintptr_t arg) { |
我们还可以写出恢复函数 restore_return():
1 | static inline void restore_return() { |
加入恢复函数后, co_yield() 里的对应逻辑变成:
1 | /// CO_NEW |
还记得对齐要求吗?你可以自己改改。
你可能好奇这个 rcx 是怎么来的,万一编译器选择了其他寄存器(比如 rdx)怎么办?你也许能想起来有个东西叫 calling convention2:
Before calling a subroutine, the caller should save the contents of certain registers that are designated caller-saved. The caller-saved registers are r10, r11, and any registers that parameters are put into. If you want the contents of these registers to be preserved across the subroutine call, push them onto the stack.
To pass parameters to the subroutine, we put up to six of them into registers (in order: rdi, rsi, rdx, rcx, r8, r9).
这说明我们作为 caller 需要保存上面说的寄存器。根据 calling convention 的改写如下:
1 | /// Save the current context to the coroutine's stack and call it. |
32 位的版本依葫芦画瓢就行:
1 | /// Save the current context to the coroutine's stack and call it. |
一些小问题
改到这里,64 位的测试基本上能跑起来了,但是 32 位的还是会段错误,出错的地方在这里:
1 | case CO_NEW: { |
查看对应汇编代码:
1 | 1484: 8b 51 14 mov 0x14(%ecx),%edx |
这里的 0xc(%esp) 就是 curr_co ,但是我的
curr_co 明明是全局变量啊为什么要相对 esp 寻址?
这就涉及到 x86 的一个细节:在位置无关代码里面,全局变量地址需要先通过
__x86.get_pc_thunk 放到某个寄存器,再从这个寄存器放到栈上3。再看看之前的实现, esp
寄存器显然还指向刚跑完的协程的栈空间,这就会出问题。有一个朴素的解决方法:保存上下文的时候一并保存
esp 。另外提一嘴,这显然有点违反 calling convention
,不过能跑就行了。
1 | static inline void stack_switch_call(void *sp, void *entry, uintptr_t arg) { |
不过如果出让执行权使用的是 co_yield() 而不是 longjmp 到
waiter,好像就不用面对这个问题(